
-
Little Birdie

Yesterday evening I started hearing this strange sound while I was working. I went outside and looked around, but I couldn’t hear it anymore. I went back inside. Then I started hearing it again. I followed the sound towards the laundry room, and there it was. A gold finch was pecking at the window. I…
-
Peter Estin Hut Trip

Last weekend I went on a hut trip. I had my friends Nick and Karen over for dinner a couple weeks ago, and they mentioned that they had some extra spots for a hut trip in a couple weeks, and asked me if I wanted to join them. At first I said no, because I…
-
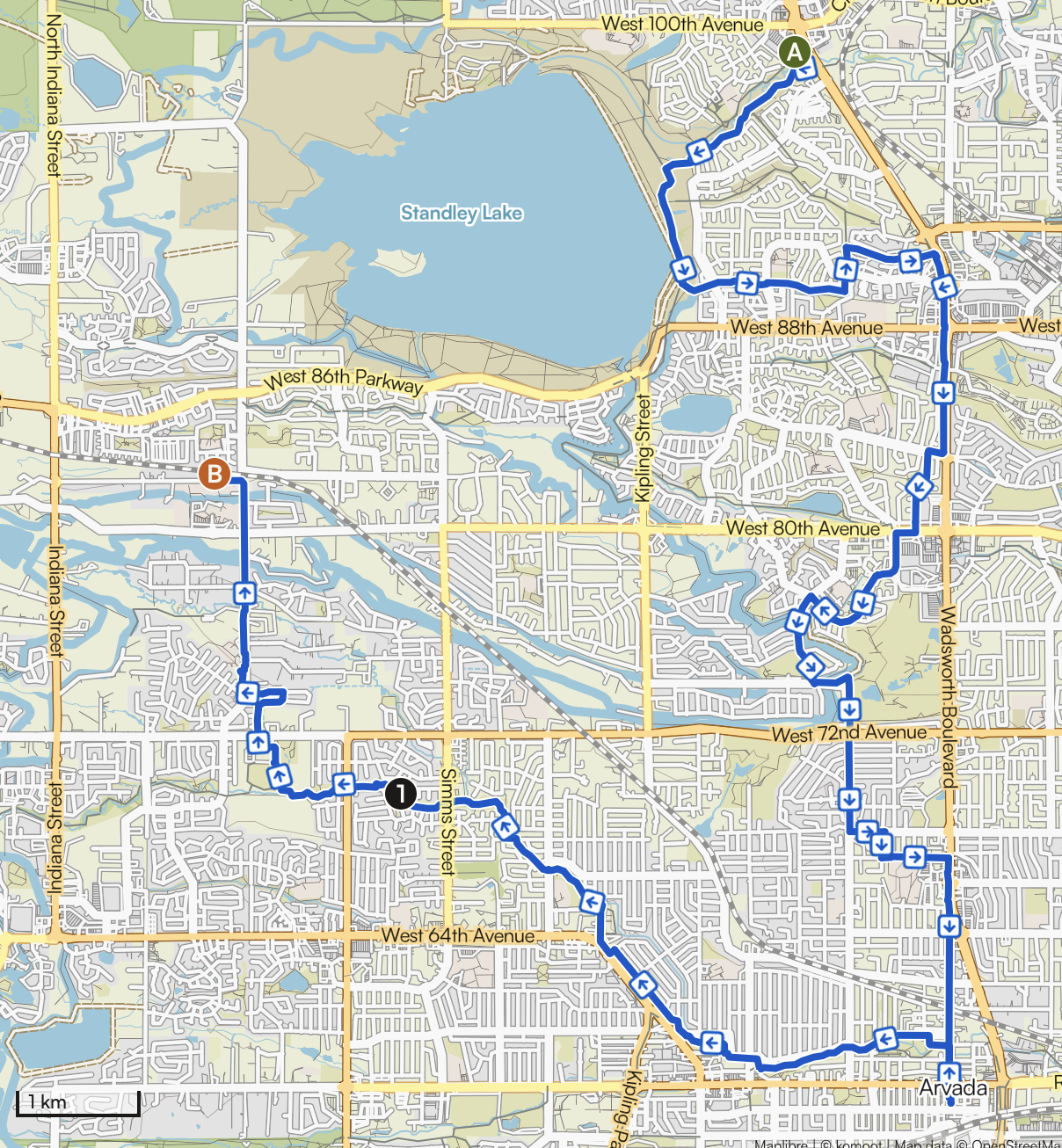
Biking along creeks

Over the past month I have taken this route three times. It takes 2-2.5 hours, depending on how hard I pedal. The first two times I headed out going east and returned west. The last time I did it in reverse (by accident really, I just started going that way out habit for some reason).…
-
Big Dry Creek trail
Today was quite nice weather again, high around 7C (45F) and sunny, so I decided to take a walk again. I had some packages to return to Amazon, so Clare dropped me off around 11 a.m. at the UPS store, and I walked home. I started off on the Big Dry Creek trail towards Standley…
-
Standley Lake

I have continued to spend a good portion of my weekends walking and exploring. Three weeks ago I decided to try to walk all the way around nearby Standley Lake. I discovered it is not possible to do so on trails, because a large portion of the area is a bald eagle breeding ground reserve.…