Overall students did very well on this assignment. Grades and comments have been committed to the repository. I also added my hmwk5.py file to the repository under resources/homework.
Class statistics for Homework 5
| mean |
53.67 |
| standard deviation |
6.76 |
-
Create a list called my_ints, with the following values: (10, 15, 24, 67, 1098, 500, 700) (2 points)
my_ints = [10, 15, 24, 67, 1098, 500, 700]
- Print the maximum value in my_ints (3 points)
- Use a for loop and a conditional to print out whether the value is an odd or even number. For example, for 10, your program should print “10 is even”. (5 points)
for my_int in my_ints:
if my_int % 2 == 0:
print my_int, "is even"
else:
print my_int, "is odd"
- Now create a new list called new_ints and fill it with values from my_ints which are divisible by 3. In addition, double each of the new values. For example, the new list should contain 30 (15*2). Use a for loop and a conditional to accomplish this task. (5 points)
new_ints = []
for my_int in my_ints:
if my_int % 3 == 0:
new_ints.append(my_int*2)
print new_ints
- Now do the same thing as in the last question, but use a list expression to accomplish the task. (5 points)
new_ints = [my_int*2 for my_int in my_ints if my_int % 3 == 0]
print new_ints
- Import the Reuters corpus from the NLTK. How many documents contain stories about coffee? (4 points)
import nltk
import nltk.corpus
from nltk.corpus import reuters
print len(reuters.fileids('coffee'))
- Print the number of words in the Reuters corpus which belong to the barley category. (5 points)
print len(reuters.words(categories='barley'))
- Create a conditional frequency distribution of word lengths from the Reuters corpus for the categories barley, corn, and rye. (8 points)
reuters_word_lengths = [(category, len(word))
for category in ['barley', 'corn', 'rye']
for word in reuters.words(categories=category)]
reuters_word_lengths_cfd = nltk.ConditionalFreqDist(reuters_word_lengths)
- Using the cfd you just created, print out a table which lists cumulative counts of word lengths (up to nine letters long) for each category. (5 points)
reuters_word_lengths_cfd.tabulate(samples=range(1,10),cumulative=True)
- Load the devilsDictionary.txt file from the ling5200 svn repository in resources/texts into the NLTK as a plaintext corpus (3 points)
from nltk.corpus import PlaintextCorpusReader
corpus_root = 'resources/texts'
wordlists = PlaintextCorpusReader(corpus_root, 'devilsDictionary.txt')
- Store a list of all the words from the Devil’s Dictionary into a variable called devil_words (4 points)
devil_words = wordlists.words('devilsDictionary.txt')
- Now create a list of words which does not include punctuation, and store it in devil_words_nopunc. Import the string module to get a handy list of punctuation marks, stored in string.punctuation. (5 points)
import string
devil_words_nopunc = [word for word in devil_words if word not in string.punctuation]
- Create a frequency distribution for each of the two lists of words from the Devil’s dictionary, one which includes punctuation, and one which doesn’t. Find the most frequently occuring word in each list. (6 points)
devil_fd = nltk.FreqDist(devil_words)
devil_nopunc_fd = nltk.FreqDist(devil_words_nopunc)
print devil_fd.max()
print devil_nopunc_fd.max()
In this homework you will practice writing your own functions to extract
information from various corpora. Please put your answers in an executable python
script named hmwk6.py, and commit it to the subversion repository. Don’t forget to use normal division.
It is due Oct. 9th and covers material up to Oct. 1st.
-
Create a function called mean_word_len, which accepts a list of words (e.g. text1 — Moby Dick), and returns the mean characters per word. You should remove punctuation and stopwords from the calculation. (10 points)
-
Create a function called mean_sent_len, which accepts a list of sentences, and returns the mean words per sentence. You should remove punctuation and stopwords from the calculation. Note that the NLTK .sents() method returns a list of lists. That is, each item in the list represents a sentence, which itself is composed of a list of words. (15 points)
- Now use your two new functions to print out the mean sentence length and the mean word length for all of the texts from the gutenberg project included in the NLTK. You should print out these statistics with one file per line, with the fileid first, and then the mean word length and sentence length. One example would be:
melville-moby_dick.txt 5.64357969913 9.79009882174
(10 points)
- Using the CMU pronouncing dictionary, create a list of all words which have 3 letters, and 2 syllables. Your final list should include just the spelling of the words. To calculate the number of syllables, use the number of vowels in the word (every vowel includes the digit 1, 2, or 0, marking primary, secondary, or no stress). (15 points)
- Imagine you are writing a play, and you are you thinking of interesting places to stage a scene. You would like it be somewhere like a house, but not exactly. Use the wordnet corpus to help you brainstorm for possible locations. First, find the hypernyms of the first definition of the word house. Then find all the hyponyms of those hypernyms, and print out the names of the words. Your output should contain one synset per line, with first the synset name, and then all of the lemma_names for that synset, e.g.:
lodge.n.05 - lodge, indian_lodge
(10 points)
Here are the slides from today’s class covering semantic relations. We also talked about automatic historical linguistics. You can try out the handy script from the repository in resources/py/auto_histling.py
Martha Palmer also gave a brief introduction to some of the corpora and databases that are available for use. Please look at the list on the linguistics website. If you are interested in using one of these, you will need to ask Martha for an account on the verbs or babel server.
 ling5200-nltk2-2-slides.pdf
ling5200-nltk2-2-slides.pdf
I have made several changes to the syllabus, including:
- Added a reading for Tue, Oct. 6th
- Changed homework schedule, so that final project proposals are due Nov. 6th
In addition, I have added a file while contains all of the notes from the class so far. You can get it from the svn repository under slides.
Here are the notes for today’s class on Semantic relations.
ling5200-nltk2-2-notes.pdf
Here are the slides for today’s class covering nltk lexical resources, python functions and modules.
We did not get to the last part about automatically doing historical linguistics. We will cover that on Thursday.
ling5200-nltk2-1-slides.pdf
Here are the notes for today’s class, covering python functions and lexical resources in the nltk.
ling5200-nltk2-1-notes.pdf
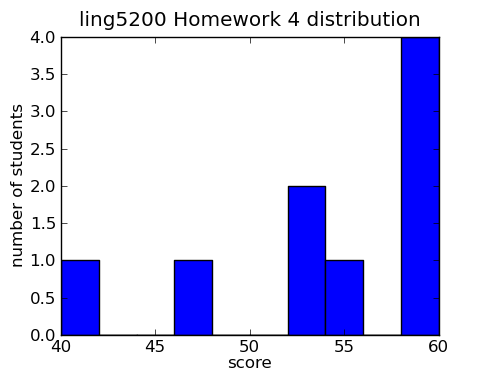
Overall, students did quite well on this assignment. Comments are in your files in the subversion repository. Run svn update from your personal directory to get the latest version. My python solution file is also in the repository under resources/hmwk
Class statistics for Homework 4
| mean |
54.3 |
| standard deviation |
4.8 |
Regular expressions
- Use grep to print out all words from the celex.txt file which have a
frequency of 100 or more, and either start with a-l, or end with m-z. Note that
the orthography column comes right before the frequency column, so this is
possible to do using a single regular expression. You should use one grouping
and several character classes. Hint 1: use negative character classes to avoid
getting stuff that is in more than one column. Hint 2: Consider what is
different between the numbers 87 and 99, vs. the numbers 100 and 154.
Here are some example words which should be included
- at (starts with a-l)
- yellow (ends with m-z)
Here are some example words which should be excluded
- omega (does not start with a-l, does not end with m-z)
- abacus (starts with a-l, but has a frequency less than 100
(10 points)
grep -E '^[^\\]*\\([a-lA-L][^\\]*|[^\\]*[m-zM-Z])\\[0-9]{3,}' celex.txt
Python
Create a python script called hmwk4.py, and put all your answers in this file.
You can use comments in the file if you like. Before each answer, print out the
question number, and a brief description. For example:
print('#2 - first 10 words in the holy grail')
- Print the first 10 words from monty python and the holy grail (text6). (3 points)
- Print the last 20 words from Moby Dick (text1). (4 points)
- Create a frequency distribution of the holy grail. Store it in the variable
called moby_dist. (4 points)
moby_dist = FreqDist(text6)
- Print the number of times the word “Grail” occurs in this text (4 points)
print(moby_dist['Grail'])
- Print the most frequent word in the Holy Grail. (Hint: note that punctuation is counted as words by the NLTK. That is the answer might be a punctuation mark). (4 points)
- Create a list which contains the word lengths of each word in the Holy
Grail(text6). Store it in a variable called holy_lengths. Do the same for Moby
Dick (text1), and store it in a variable called moby_lengths. (6 points)
moby_lengths = [len(w) for w in text1]
holy_lengths = [len(w) for w in text6]
- Create a frequency distribution of word lengths for Moby Dick and The Holy Grail. Store the distributions in variables called moby_len_dist and holy_len_dist respectively. (6 points)
moby_len_dist = FreqDist(moby_lengths)
holy_len_dist = FreqDist(holy_lengths)
- Print the most commonly occuring word length for Moby Dick and for The Holy Grail. (Use one command for each) (5 points)
print(moby_len_dist.max())
print(holy_len_dist.max())
- Calculate the mean word length for Moby Dick and The Holy Grail. You can use the sum() function to calculate the total number of characters in the text. For example, sum([22, 24, 3]) returns 49. Store the results in variables holy_mean_len and moby_mean_len respectively. (6 points)
holy_mean_len = sum(holy_lengths)/len(holy_lengths)
moby_mean_len = sum(moby_lengths)/len(moby_lengths)
- Create a list of words from Moby Dick which have more than 3 letters, and
less than 7 letters. Store it in a variable called four_to_six. (8 points)
four_to_six = [w for w in text1 if len(w) > 3 and len(w) < 7]
In this homework you will practice loading and extracting information from various corpora, and calculating word frequency and conditional word frequency. There will be questions about conditionals, loops, and list expressions. Please put your answers in an executable python script named hmwk5.py, and commit it to the subversion repository.
It is due Oct. 2nd and covers material up to Sep. 24th.
-
Create a list called my_ints, with the following values: (10, 15, 24, 67, 1098, 500, 700) (2 points)
- Print the maximum value in my_ints (3 points)
- Use a for loop and a conditional to print out whether the value is an odd or even number. For example, for 10, your program should print “10 is even”. (5 points)
- Now create a new list called new_ints and fill it with values from my_ints which are divisible by 3. In addition, double each of the new values. For example, the new list should contain 30 (15*2). Use a for loop and a conditional to accomplish this task. (5 points)
- Now do the same thing as in the last question, but use a list expression to accomplish the task. (5 points)
- Import the Reuters corpus from the NLTK. How many documents contain stories about coffee? (4 points)
- Print the number of words in the Reuters corpus which belong to the barley category. (5 points)
- Create a conditional frequency distribution of word lengths from the Reuters corpus for the categories barley, corn, and rye. (8 points)
- Using the cfd you just created, print out a table which lists cumulative counts of word lengths (up to nine letters long) for each category. (5 points)
- Load the devilsDictionary.txt file from the ling5200 svn repository in resources/texts into the NLTK as a plaintext corpus (3 points)
- Store a list of all the words from the Devil’s Dictionary into a variable called devil_words (4 points)
- Now create a list of words which does not include punctuation, and store it in devil_words_nopunc. Import the string module to get a handy list of punctuation marks, stored in string.punctuation. (5 points)
- Create a frequency distribution for each of the two lists of words from the Devil’s dictionary, one which includes punctuation, and one which doesn’t. Find the most frequently occuring word in each list. (6 points)
Here are the slides from today’s class, covering an introduction to various corpora in the NLTK, and a discussion of calculating conditional frequency distributions.
ling5200-nltk2-slides.pdf
