In this homework you will expand upon some of the code you wrote in homework 7, using the functions you wrote to calculate mean word and sentence length. However, you will now add the ability to read from stdin. Note that for this assignment, you should not print out any information about the questions. You should only print out information as requested in the last question. Make sure to read all questions before starting the assignment. It is due Oct. 23rd and covers material up to Oct. 15th.
-
Readability measures are used to score the reading difficulty of a text, for the purposes of selecting texts of appropriate difficulty for language learners. Let us define μw to be the average number of letters per word, and μs to be the average number of words per sentence, in a given text. The Automated Readability Index (ARI) of the text is defined to be: 4.71 μw + 0.5 μs – 21.43. Define a function which computes the ARI score. It should accept two arguments – the mean word length, and the mean sentence length. (5 points)
-
One feature of English is that it is easy to turn verbs into nouns and adjectives, by using participles. For example, in the phrase the burning bush, the verb burn is used as an adjective, by using the present participle form. Create a function called verb_adjectives which uses the findall method from the NLTK to find present participles used as adjectives. For simplicity, find only adjectives that are preceded by an article (a, an, the). Make sure that they have a word following them (not punctuation). The function should accept a list of tokens, as returned by the words() function in the NLTK. Note that all present participles in English end in ing. Unfortunately, the nltk findall function which we used in class prints out the words, instead of just returning them. This means that we cannot use it in a function. (Go ahead and try to use it, and convince yourself why it is generally bad to print stuff from functions, instead of just returning results (unless the function’s only purpose is to print something out, e.g. pprint)). So, I will get you started on the functions you need to use:
regexp = r'<a><.*><man>'
moby = nltk.Text( gutenberg .words('melville - moby_dick .txt '))
bracketed = nltk.text.TokenSearcher(moby)
hits = bracketed.findall(regexp)
This returns a list of lists, where each list is composed of the 3 word phrase which matches. So your main task is to come up with the correct regular expression. (7 points)
- As we have seen in class, most computational linguistics involves a combination of automation and hand-checking. Let’s refine our verb_adjectives function by ensuring that none of the words following the adjective are in the stopwords corpus. Without doing this, we get results like['an', 'understanding', 'of'], where understanding is being used as a noun, not an adjective. Use a list expression to remove all hits where the third word in the list is a stopword. (7 points)
- Add three more options to your script, -j (–adj), -a (–ari), and -n (–noheader). Note that if the –ari option is specified, then you should also print out the mean word length and mean sentence length. If no options are given, it should function the same as if the options -wsaj were given. Your options should now look like:
-w --word print only mean word length
-s --sent print only mean sentence length
-h --help print this help information and exit
-a --ari print ari statistics
-j --adj print mean number of adjectival verbs per sentence
-n --noheader do not print a header line
(10 points)
- Now modify your script so that it can accept either stdin or one or more files as input. Use the stdin_or_file() function in args.py as an example. Your script will no longer print out usage information when no arguments are given, as was the case for homework 7. Create a function called calc_text_stats to handle all the calculations. That way you can call this function either multiple times (once per file, if files are specified), or just once, if reading from stdin. This will make your code more readable. You should also make sure to handle the two new options, for ari and adj. (20 points)
-
Now print out the mean word length, mean sentence length, ari, and the mean number of present participles used as adjectives per sentence for huckFinn, tomSawyeer, Candide, and devilsDictionary. Pipe the output to sort, and sort by ari. Your output should be similar to homework 7. Save the bash command you used in a script called ari. Make sure that it is executable. (11 points)
It seems that several people are still a little bit confused about what I would like you to do for homework 7. Your program should function much like any other UNIX program. For example, consider the wc program. I can use wc to count the words from several files. (From the resources/py directory)
wc args.py opts.py auto_histling.py
I specified three files on the command line, separated by spaces.
The output should be something like:
37 116 895 args.py
34 105 847 opts.py
77 335 3167 auto_histling.py
148 556 4909 total
Note that the columns are nicely aligned. Your program should work in a similar way, except that it will be printing out mean word and sentence length.
The getopt method will return a list of options and arguments. The arguments should be the filenames you specified on the command line. You will want to loop over the arguments and process each file one at a time.
Rob
Most students did well on this homework.
I made an error in the description for question 3. I had the wrong values for mean word and sentence length for Moby Dick, as I had not converted words to lowercase before comparing with the stopword corpus. I have corrected that in the solution here, and I did not take off any points if you did not convert to lower case. My solution python file is in the repository under resources/homework
I would also like to remind you of a couple things:
- make sure your python files are executable
- have a proper shbang line as the very first line of your file.
- use 4 spaces for indenting, not tabs, and please do not mix tabs and spaces
Starting with homework 7, I will begin taking off 5 points each for any of the above mistakes.
Class statistics for Homework 5
| mean |
49.71 |
| standard deviation |
14.14 |
-
Create a function called mean_word_len, which accepts a list of words (e.g. text1 — Moby Dick), and returns the mean characters per word. You should remove punctuation and stopwords from the calculation. (10 points)
from pprint import pprint
import nltk
from nltk.corpus import stopwords
import string
def mean_word_len(words):
eng_stopwords = stopwords.words('english')
words_no_punc = [w for w in words
if w not in string.punctuation and w.lower() not in eng_stopwords]
num_words = len(words_no_punc)
num_chars = sum([len(w) for w in words_no_punc])
return (num_chars / num_words)
-
Create a function called mean_sent_len, which accepts a list of sentences, and returns the mean words per sentence. You should remove punctuation and stopwords from the calculation. Note that the NLTK .sents() method returns a list of lists. That is, each item in the list represents a sentence, which itself is composed of a list of words. (15 points)
import string
def mean_sent_len(sents):
eng_stopwords = stopwords.words('english')
words_no_punc = [w for s in sents for w in s
if w not in string.punctuation and w.lower() not in eng_stopwords]
num_words = len(words_no_punc)
num_sents = len(sents)
return (num_words / num_sents)
- Now use your two new functions to print out the mean sentence length and the mean word length for all of the texts from the gutenberg project included in the NLTK. You should print out these statistics with one file per line, with the fileid first, and then the mean word length and sentence length. One example would be:
melville-moby_dick.txt 5.94330208809 8.86877613075
(10 points)
from nltk.corpus import gutenberg
for fileid in gutenberg.fileids():
words = gutenberg.words(fileid)
sents = gutenberg.sents(fileid)
print fileid, mean_word_len(words), mean_sent_len(sents)
- Using the CMU pronouncing dictionary, create a list of all words which have 3 letters, and 2 syllables. Your final list should include just the spelling of the words. To calculate the number of syllables, use the number of vowels in the word (every vowel includes the digit 1, 2, or 0, marking primary, secondary, or no stress). (15 points)
entries = nltk.corpus.cmudict.entries()
stress_markers = ['0','1','2']
three_letter_two_syl_words = []
for word , pron in entries :
if len(word) == 3:
syllables = 0
for phoneme in pron:
for marker in stress_markers:
if marker in phoneme:
syllables += 1
if syllables == 2:
three_letter_two_syl_words.append((word,pron))
pprint(three_letter_two_syl_words)
- Imagine you are writing a play, and you are you thinking of interesting places to stage a scene. You would like it be somewhere like a house, but not exactly. Use the wordnet corpus to help you brainstorm for possible locations. First, find the hypernyms of the first definition of the word house. Then find all the hyponyms of those hypernyms, and print out the names of the words. Your output should contain one synset per line, with first the synset name, and then all of the lemma_names for that synset, e.g.:
lodge.n.05 - lodge, indian_lodge
(10 points)
from nltk.corpus import wordnet
house = wordnet.synsets('house')[0]
house_hypernyms = wordnet.synset(house.name).hypernyms()
for hypernym in house_hypernyms:
print "-------", hypernym.name, "---------"
for hyponym in hypernym.hyponyms():
print hyponym.name, " - ", ", ".join(hyponym.lemma_names)
In this homework you will expand upon some of the code you wrote homework 6, using the functions you wrote to calculate mean word and sentence length. However, now you will accept command line arguments and options to use these functions, and print the output in a nice-looking format. Make sure to read all questions before starting the assignment. It is due Oct. 16th and covers material up to Oct. 8th.
-
From BASH, use svn to copy your hmwk6.py file to hmwk7.py. This will preserve all of the history from hmwk6, so you can see how you have improved your code from homework 6 to homework 7. (3 points)
- Create a function called usage, which prints out information about how the script should be used, including what arguments should be specified, and what options are possible. It should take one argument, which is the name of the script file. (7 points)
- Write your script to process the following options. Look at opts.py under resources/py for an example. If both -s and -w are specified, it should print out both options. (14 points)
-w --word print only mean word length
-s --sent print only mean sentence length
-h --help print this help information and exit
-
Instead of specifying which texts to process in your code, change your code so
that it accepts filenames from the command line. Look at the args.py file
under resources/py for an example of how to do this. Your code should print out
the name of each file (you can use the os.path.basename function to print out only the name of the file) specified on the command line, and the mean word length
and sentence length, with a width of 13 and a precision of 2. Note that it
should only print word length or sentence length if that option has been
specified. If no files are specified, it should print the usage information
and exit. Also note that after reading in a text you will have to first convert
it to a list of words or sentences using the tokenize functions in the nltk,
before calculating the mean word length and sentence length with the functions
you defined in homework 6. See chapter 13 in the notes for examples on how to
tokenize text to homework 5 for how to do this. The first line of output should
be a line of headers describing the columns (28 points) Here is some example
output:
filename mean_word_len mean_sent_len
fooey 3.45 13.47
bar 3.15 9.29
-
Use your script to print out mean word length and sentence length for huckFinn, tomSawyeer, Candide, and devilsDictionary (in resources/texts). Save the output to a file called hmwk7_stats.txt in your personal directory, and commit it to the svn repository. Show the command you use in BASH. Make your paths relative to the root of your working copy of the repository. Do the same command, but also try the -s and -w option, and print to the screen. (8 points)
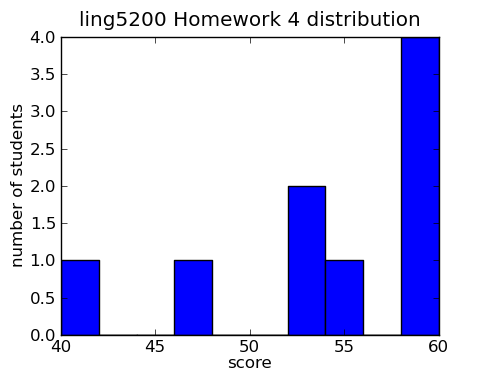
Overall students did very well on this assignment. Grades and comments have been committed to the repository. I also added my hmwk5.py file to the repository under resources/homework.
Class statistics for Homework 5
| mean |
53.67 |
| standard deviation |
6.76 |
-
Create a list called my_ints, with the following values: (10, 15, 24, 67, 1098, 500, 700) (2 points)
my_ints = [10, 15, 24, 67, 1098, 500, 700]
- Print the maximum value in my_ints (3 points)
- Use a for loop and a conditional to print out whether the value is an odd or even number. For example, for 10, your program should print “10 is even”. (5 points)
for my_int in my_ints:
if my_int % 2 == 0:
print my_int, "is even"
else:
print my_int, "is odd"
- Now create a new list called new_ints and fill it with values from my_ints which are divisible by 3. In addition, double each of the new values. For example, the new list should contain 30 (15*2). Use a for loop and a conditional to accomplish this task. (5 points)
new_ints = []
for my_int in my_ints:
if my_int % 3 == 0:
new_ints.append(my_int*2)
print new_ints
- Now do the same thing as in the last question, but use a list expression to accomplish the task. (5 points)
new_ints = [my_int*2 for my_int in my_ints if my_int % 3 == 0]
print new_ints
- Import the Reuters corpus from the NLTK. How many documents contain stories about coffee? (4 points)
import nltk
import nltk.corpus
from nltk.corpus import reuters
print len(reuters.fileids('coffee'))
- Print the number of words in the Reuters corpus which belong to the barley category. (5 points)
print len(reuters.words(categories='barley'))
- Create a conditional frequency distribution of word lengths from the Reuters corpus for the categories barley, corn, and rye. (8 points)
reuters_word_lengths = [(category, len(word))
for category in ['barley', 'corn', 'rye']
for word in reuters.words(categories=category)]
reuters_word_lengths_cfd = nltk.ConditionalFreqDist(reuters_word_lengths)
- Using the cfd you just created, print out a table which lists cumulative counts of word lengths (up to nine letters long) for each category. (5 points)
reuters_word_lengths_cfd.tabulate(samples=range(1,10),cumulative=True)
- Load the devilsDictionary.txt file from the ling5200 svn repository in resources/texts into the NLTK as a plaintext corpus (3 points)
from nltk.corpus import PlaintextCorpusReader
corpus_root = 'resources/texts'
wordlists = PlaintextCorpusReader(corpus_root, 'devilsDictionary.txt')
- Store a list of all the words from the Devil’s Dictionary into a variable called devil_words (4 points)
devil_words = wordlists.words('devilsDictionary.txt')
- Now create a list of words which does not include punctuation, and store it in devil_words_nopunc. Import the string module to get a handy list of punctuation marks, stored in string.punctuation. (5 points)
import string
devil_words_nopunc = [word for word in devil_words if word not in string.punctuation]
- Create a frequency distribution for each of the two lists of words from the Devil’s dictionary, one which includes punctuation, and one which doesn’t. Find the most frequently occuring word in each list. (6 points)
devil_fd = nltk.FreqDist(devil_words)
devil_nopunc_fd = nltk.FreqDist(devil_words_nopunc)
print devil_fd.max()
print devil_nopunc_fd.max()
In this homework you will practice writing your own functions to extract
information from various corpora. Please put your answers in an executable python
script named hmwk6.py, and commit it to the subversion repository. Don’t forget to use normal division.
It is due Oct. 9th and covers material up to Oct. 1st.
-
Create a function called mean_word_len, which accepts a list of words (e.g. text1 — Moby Dick), and returns the mean characters per word. You should remove punctuation and stopwords from the calculation. (10 points)
-
Create a function called mean_sent_len, which accepts a list of sentences, and returns the mean words per sentence. You should remove punctuation and stopwords from the calculation. Note that the NLTK .sents() method returns a list of lists. That is, each item in the list represents a sentence, which itself is composed of a list of words. (15 points)
- Now use your two new functions to print out the mean sentence length and the mean word length for all of the texts from the gutenberg project included in the NLTK. You should print out these statistics with one file per line, with the fileid first, and then the mean word length and sentence length. One example would be:
melville-moby_dick.txt 5.64357969913 9.79009882174
(10 points)
- Using the CMU pronouncing dictionary, create a list of all words which have 3 letters, and 2 syllables. Your final list should include just the spelling of the words. To calculate the number of syllables, use the number of vowels in the word (every vowel includes the digit 1, 2, or 0, marking primary, secondary, or no stress). (15 points)
- Imagine you are writing a play, and you are you thinking of interesting places to stage a scene. You would like it be somewhere like a house, but not exactly. Use the wordnet corpus to help you brainstorm for possible locations. First, find the hypernyms of the first definition of the word house. Then find all the hyponyms of those hypernyms, and print out the names of the words. Your output should contain one synset per line, with first the synset name, and then all of the lemma_names for that synset, e.g.:
lodge.n.05 - lodge, indian_lodge
(10 points)
Overall, students did quite well on this assignment. Comments are in your files in the subversion repository. Run svn update from your personal directory to get the latest version. My python solution file is also in the repository under resources/hmwk
Class statistics for Homework 4
| mean |
54.3 |
| standard deviation |
4.8 |
Regular expressions
- Use grep to print out all words from the celex.txt file which have a
frequency of 100 or more, and either start with a-l, or end with m-z. Note that
the orthography column comes right before the frequency column, so this is
possible to do using a single regular expression. You should use one grouping
and several character classes. Hint 1: use negative character classes to avoid
getting stuff that is in more than one column. Hint 2: Consider what is
different between the numbers 87 and 99, vs. the numbers 100 and 154.
Here are some example words which should be included
- at (starts with a-l)
- yellow (ends with m-z)
Here are some example words which should be excluded
- omega (does not start with a-l, does not end with m-z)
- abacus (starts with a-l, but has a frequency less than 100
(10 points)
grep -E '^[^\\]*\\([a-lA-L][^\\]*|[^\\]*[m-zM-Z])\\[0-9]{3,}' celex.txt
Python
Create a python script called hmwk4.py, and put all your answers in this file.
You can use comments in the file if you like. Before each answer, print out the
question number, and a brief description. For example:
print('#2 - first 10 words in the holy grail')
- Print the first 10 words from monty python and the holy grail (text6). (3 points)
- Print the last 20 words from Moby Dick (text1). (4 points)
- Create a frequency distribution of the holy grail. Store it in the variable
called moby_dist. (4 points)
moby_dist = FreqDist(text6)
- Print the number of times the word “Grail” occurs in this text (4 points)
print(moby_dist['Grail'])
- Print the most frequent word in the Holy Grail. (Hint: note that punctuation is counted as words by the NLTK. That is the answer might be a punctuation mark). (4 points)
- Create a list which contains the word lengths of each word in the Holy
Grail(text6). Store it in a variable called holy_lengths. Do the same for Moby
Dick (text1), and store it in a variable called moby_lengths. (6 points)
moby_lengths = [len(w) for w in text1]
holy_lengths = [len(w) for w in text6]
- Create a frequency distribution of word lengths for Moby Dick and The Holy Grail. Store the distributions in variables called moby_len_dist and holy_len_dist respectively. (6 points)
moby_len_dist = FreqDist(moby_lengths)
holy_len_dist = FreqDist(holy_lengths)
- Print the most commonly occuring word length for Moby Dick and for The Holy Grail. (Use one command for each) (5 points)
print(moby_len_dist.max())
print(holy_len_dist.max())
- Calculate the mean word length for Moby Dick and The Holy Grail. You can use the sum() function to calculate the total number of characters in the text. For example, sum([22, 24, 3]) returns 49. Store the results in variables holy_mean_len and moby_mean_len respectively. (6 points)
holy_mean_len = sum(holy_lengths)/len(holy_lengths)
moby_mean_len = sum(moby_lengths)/len(moby_lengths)
- Create a list of words from Moby Dick which have more than 3 letters, and
less than 7 letters. Store it in a variable called four_to_six. (8 points)
four_to_six = [w for w in text1 if len(w) > 3 and len(w) < 7]
In this homework you will practice loading and extracting information from various corpora, and calculating word frequency and conditional word frequency. There will be questions about conditionals, loops, and list expressions. Please put your answers in an executable python script named hmwk5.py, and commit it to the subversion repository.
It is due Oct. 2nd and covers material up to Sep. 24th.
-
Create a list called my_ints, with the following values: (10, 15, 24, 67, 1098, 500, 700) (2 points)
- Print the maximum value in my_ints (3 points)
- Use a for loop and a conditional to print out whether the value is an odd or even number. For example, for 10, your program should print “10 is even”. (5 points)
- Now create a new list called new_ints and fill it with values from my_ints which are divisible by 3. In addition, double each of the new values. For example, the new list should contain 30 (15*2). Use a for loop and a conditional to accomplish this task. (5 points)
- Now do the same thing as in the last question, but use a list expression to accomplish the task. (5 points)
- Import the Reuters corpus from the NLTK. How many documents contain stories about coffee? (4 points)
- Print the number of words in the Reuters corpus which belong to the barley category. (5 points)
- Create a conditional frequency distribution of word lengths from the Reuters corpus for the categories barley, corn, and rye. (8 points)
- Using the cfd you just created, print out a table which lists cumulative counts of word lengths (up to nine letters long) for each category. (5 points)
- Load the devilsDictionary.txt file from the ling5200 svn repository in resources/texts into the NLTK as a plaintext corpus (3 points)
- Store a list of all the words from the Devil’s Dictionary into a variable called devil_words (4 points)
- Now create a list of words which does not include punctuation, and store it in devil_words_nopunc. Import the string module to get a handy list of punctuation marks, stored in string.punctuation. (5 points)
- Create a frequency distribution for each of the two lists of words from the Devil’s dictionary, one which includes punctuation, and one which doesn’t. Find the most frequently occuring word in each list. (6 points)
Overall students did quite well with this assignment. I have made comments in the files you submitted, which have now been updated in the subversion repository. To see the changes, open your terminal, change the directory to <myling5200>/students/<yourname>, and type svn update. Replace <myling5200> and <yourname> with the path to your working copy and your username respectively.
Class statistics for Homework 3
| mean |
53.1 |
| standard deviation |
8.0 |
UNIX
- Using the celex.txt file, calculate the ratio of heterosyllabic vs. tautosyllabic st clusters. That is, how frequently do words contain an st cluster that is within a syllable, vs. how frequently they contain an st cluster that spans two syllables. Note that each word contains a syllabified transcription where syllables are surrounded by brackets []. For example, abacus has three syllables, [&][b@][k@s]. You should use grep and bc to calculate the ratio (also compare to the question from hmwk 2 to computer the average number of letters per word for each entry in the devils dictionary). 10 points
echo "`grep -Ec 's\]\[t' celex.txt` / `grep -Ec '(\[st|st\])' celex.temp `" |bc -l
- How many entries in the devils dictionary have more than 6 letters? Use grep to find out (5 points)
grep -Ec '^[A-Z-]{7,}.*, [a-z]{1,3}\.' devilsDictionary.txt
Subversion
For this homework, submit it via subversion by adding it into your own directory. Make at least 2 separate commits. When you are finished, make sure to say so in your log message.
- Create a new file called hmwk3_<yourname>.txt, and add it to the svn repository. Show the commands you used (5 points)
pwd #myling5200/students/<myname>
touch hmwk3_<myname>.txt
svn add hmwk3_<myname>.txt
svn commit -m 'adding homework 3 file'
- Show the log of all changes you made to your homework 3 file. Show the commands you used (5 points)
pwd #myling5200/students/<myname>
svn log hmwk3_<myname>.txt
- Find all log messages pertaining to the slides which contain grep. You will need to use a pipe. Your command should print out not only the line which contains grep, but also the 2 preceding lines. Search the grep manual for “context” to find the appropriate option. (7 points)
pwd #myling5200
svn log slides | grep -EiB 'grep'
- Show the changes to your homework 3 file between the final version and the version before that. Show the commands you used (5 points)
pwd #myling5200/students/<myname>
svn diff -r <number>:<number> hmwk3_<myname>.txt
Python
-
Calculate the percentage of indefinite articles in Moby Dick using the NLTK. You can use the percentage function defined in chapter 1.1 (8 points)
percentage((text1.count('a')) + text1.count('an'), len(text1))
-
Using the dispersion_plot function in the nltk, find 1 word which has been used with increasing frequency in the inaugural address, and one which has been used with decreasing frequency. You can base your decision of increasing vs. decreasing simply by using visual inspection of the graphs. (5 points)
- Use the random module to generate 2 random integers between 10 and 100, and then calculate the quotient of the first number divided by the second. Make sure to use normal division, not integer division. Look at the help for the random module to find the appropriate function (10 points)
from __future__ import division
import random
print(random.randint(10,100) / random.randint(10,100))
Extra credit:
Use perl and regular expressions to strip the answers from the solutions to homework one. First, download the solution. You might also want to look at a blog entry on perl slurping for hints. (3 extra points)
perl =pe '$string = do { local ( $/ ); <>}; $string=~s/<(code|pre)>.*?<\/pre>//gs;' < hmwk2.solution > hmwk2.question
This homework involves some more practice with regular expressions, as well as using lists with python, and making some word frequency measurements with the NLTK. It covers material up to Sep. 17th.
Regular expressions
- Use grep to print out all words from the celex.txt file which have a
frequency of 100 or more, and either start with a-l, or end with m-z. Note that
the orthography column comes right before the frequency column, so this is
possible to do using a single regular expression. You should use one grouping
and several character classes. Hint 1: use negative character classes to avoid
getting stuff that is in more than one column. Hint 2: Consider what is
different between the numbers 87 and 99, vs. the numbers 100 and 154.
Here are some example words which should be included
- at (starts with a-l)
- yellow (ends with m-z)
Here are some example words which should be excluded
- omega (does not start with a-l, does not end with m-z)
- abacus (starts with a-l, but has a frequency less than 100
(10 points)
Python
Create a python script called hmwk4.py, and put all your answers in this file.
You can use comments in the file if you like. Before each answer, print out the
question number, and a brief description. For example:
print('#2 - first 10 words in the holy grail')
- Print the first 10 words from monty python and the holy grail (text6). (3 points)
- Print the last 20 words from Moby Dick (text1). (4 points)
- Create a frequency distribution of the holy grail. Store it in the variable
called moby_dist. (4 points)
- Print the number of times the word “Grail” occurs in this text (4 points)
- Print the most frequent word in the Holy Grail. (Hint: note that punctuation is counted as words by the NLTK, so it is possible that the most frequent word might actually be a punctuation mark). (4 points)
- Create a list which contains the word lengths of each word in the Holy
Grail(text6). Store it in a variable called holy_lengths. Do the same for Moby
Dick (text1), and store it in a variable called moby_lengths. (6 points)
- Create a frequency distribution of word lengths for Moby Dick and The Holy Grail. Store the distributions in variables called moby_len_dist and holy_len_dist respectively. (6 points)
- Print the most commonly occuring word length for Moby Dick and for The Holy Grail. (Use one command for each) (5 points)
- Calculate the mean word length for Moby Dick and The Holy Grail. You can use the sum() function to calculate the total number of characters in the text. For example, sum([22, 24, 3]) returns 49. Store the results in variables holy_mean_len and moby_mean_len respectively. (6 points)
- Create a list of words from Moby Dick which have more than 3 letters, and
less than 7 letters. Store it in a variable called four_to_six. (8 points)
