
-
Be yourself

Today I watched Rick Beato’s interview of Flea, the bassist from the Red Hot Chili Peppers. I have been big fans of both of them for many years (much longer for Flea). I learned quite a lot from the interview. I knew that Flea had started on trumpet, but I hadn’t realized how much he…
-
Musical November

Over the last couple weeks I have been very musically involved. Nearly every day I was either playing or listening to a concert. And when I wasn’t doing one of those, I found time to practice drums and/or keyboard most days as well. Monday, Nov. 3rd – jazz jam session at the Kuckucksnest in Aachen.…
-
Red letter day
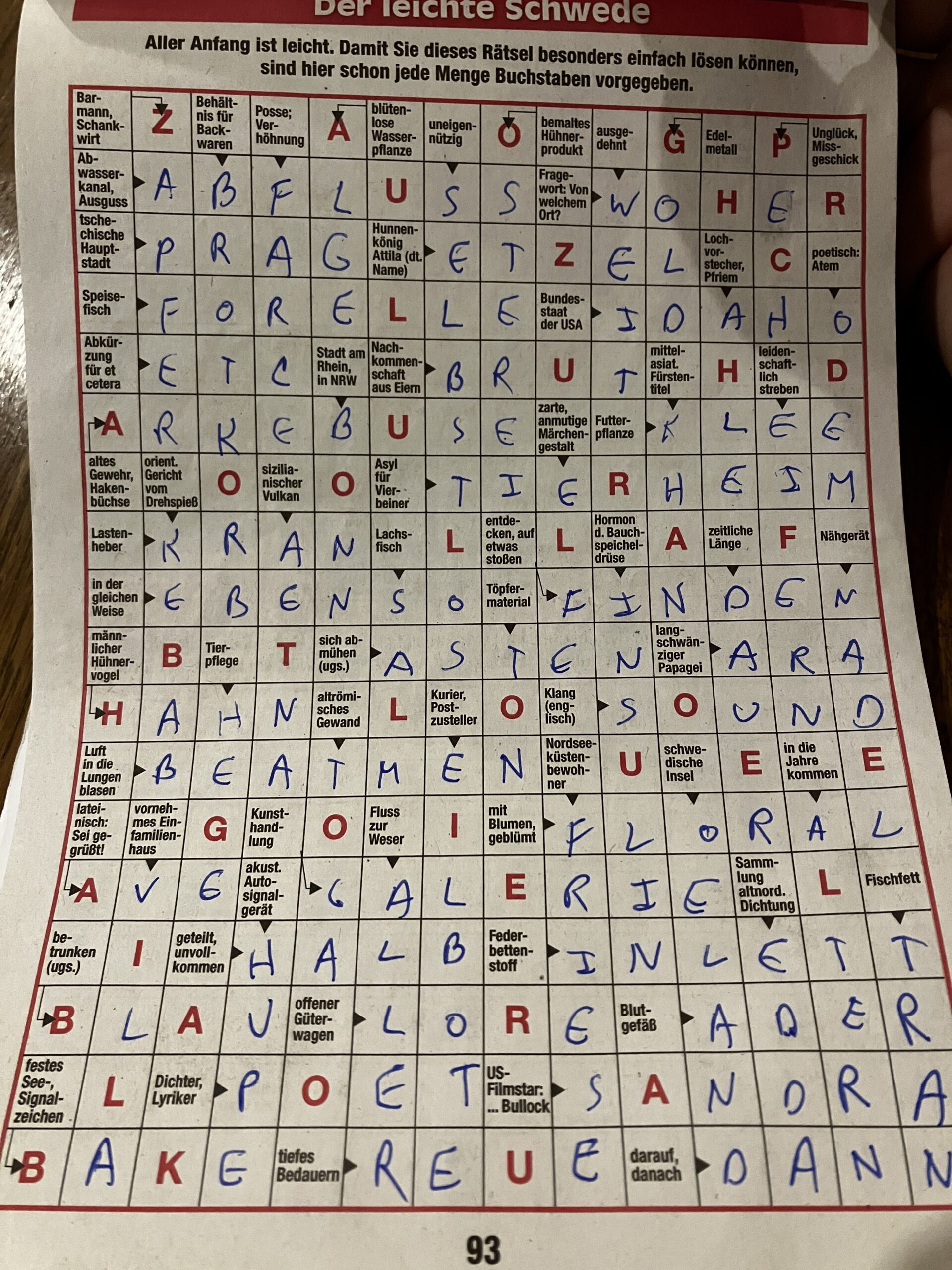
Almost two years ago, my friends Thomas and Ulli gave me a crossword puzzle book while I was in rehab recovering from a traumatic brain injury. I have been working on that book a little bit at a time since then. For quite some time, I mostly worked on it in waiting rooms for doctors,…
-
Expect the unknowns
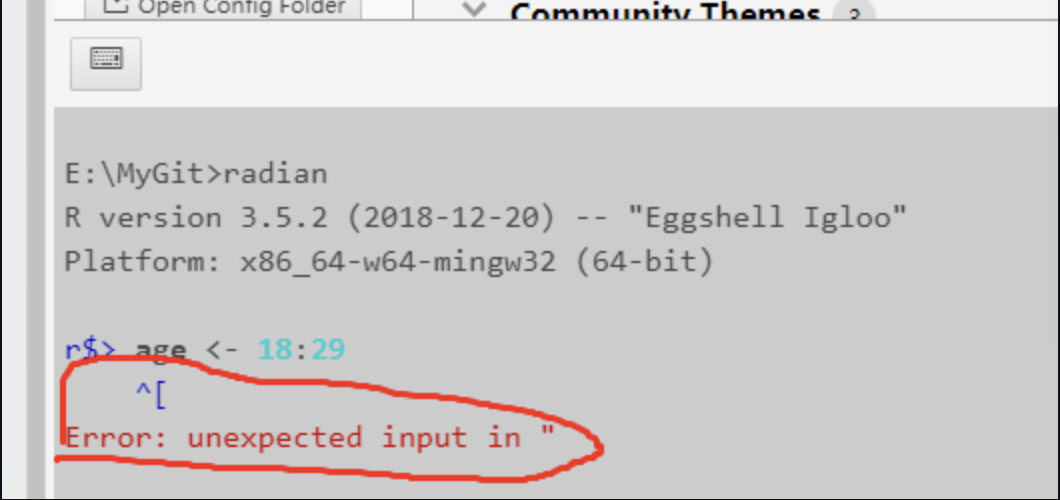
In 2002 Donald Rumsfeld made this statement about weapons of mass destruction in Iraq Reports that say that something hasn’t happened are always interesting to me, because as we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there…
-
MacOS/UNIX tip of the day: Opening many urls at once
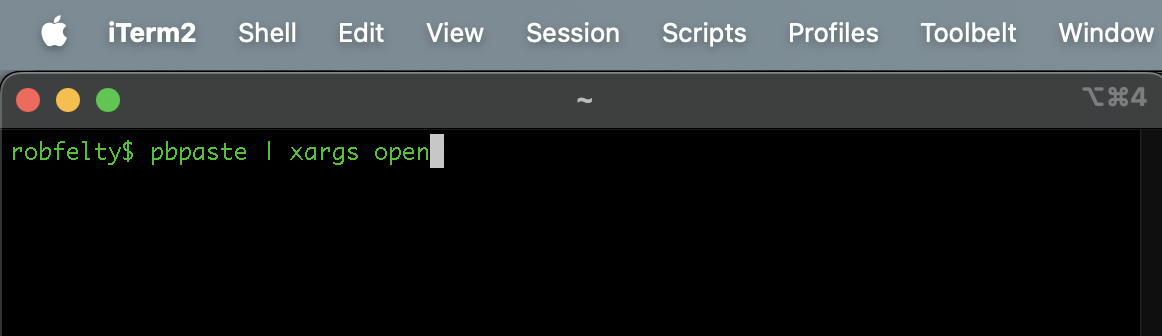
Today I needed to use a tool to look up information about 30 or so blogs at work. The tool is a web-based internal tool, which accepts a blog_id as a parameter in the url. I used some UNIX magic to extract these from some other information, so that I had a simple list in…